
GCID Cores
The long-range objective of the J. Craig Venter Institute (JCVI) Genomic Center for Infectious Diseases (GCID) is to develop basic knowledge of infectious disease biology through the application of genomic technologies. JCVI has been engaged in this research field since our founding in 1992. The Program is based on the application of innovative genomics-based approaches to study pathogens and determinants of their virulence, drug-resistance, immune-evasion and interactions with the host, and the host microbiome. The Program builds on our experience as an NIAID Microbial Sequencing Center (MSC) and Genomic Sequencing Center for Infectious Diseases (GSCID).
GCID Activities:
Below is an overview of the Center's capabilities illustrating the key components, major activities and outputs and potential impacts.
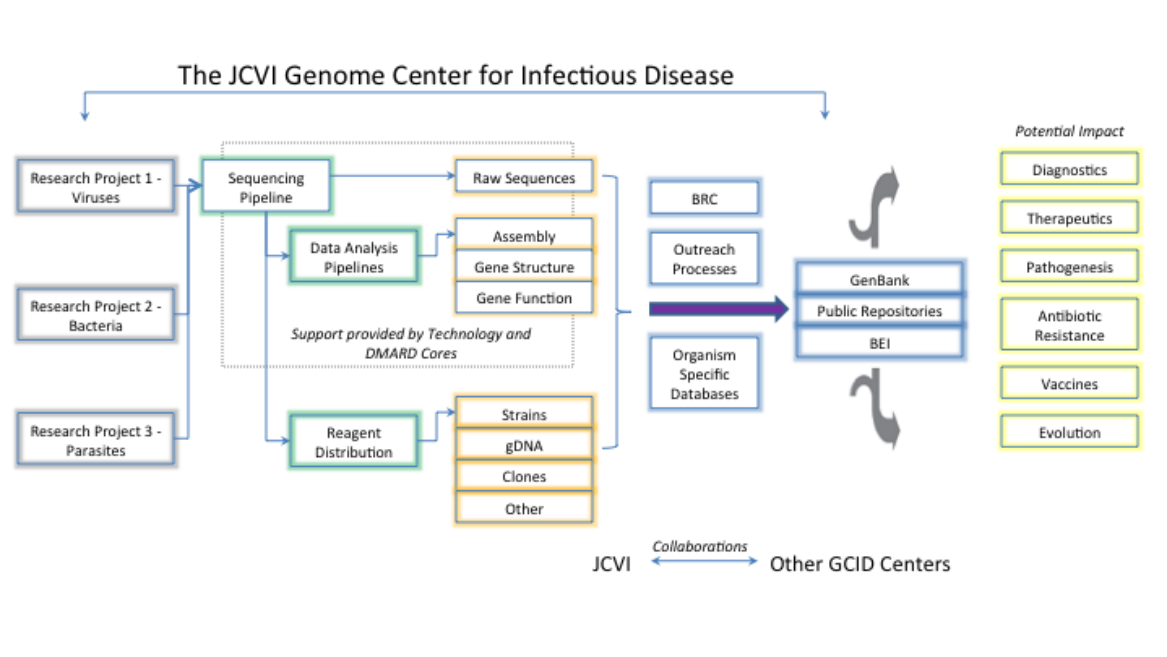
Cores:
The Center is supported by the Technology and Data Management, Analysis and Resources Dissemination (DMARD) Cores which:
- Provide high throughput, high quality, and low cost genomic sequencing and genotyping services that generate a variety of publicly available genomic data for a diverse set of projects.
- Assemble and annotate genomes as well as analyzing genotype data.
- Identify, evaluate, and implement new sequencing and genotyping technologies.
- Integrate data with other infectious diseases resource centers.
- Collaborate with basic and clinical infectious diseases scientists and their communities.
- Maintain community collaborations through technical workshops.
- Educate and train infectious diseases scientists on GCID tools and methods.
Sequencing:
The appropriate technology and platform for each project will be selected based on the genomic diversity of the organism being studied, the organism and strains being sequenced/genotyped, and/or the scientific questions being asked. The GCID will leverage a combination of MiSeq, HiSeq, IonTorrent, and PacBio sequencing platforms while continuing to identify, evaluate, and implement appropriate new sequencing technologies into the sequencing production pipelines.
Bioinformatics:
GCID data generation and processing will be managed and supported by a sophisticated bioinformatics systems, including a Laboratory Information Management System, automated pipelines for quality control of sequence data, genome assembly and finishing, and automated and manually-assisted annotation. In addition, the ontologies based metadata tracking system (O-META) will be enhanced. Informatics tools and infrastructure also underpin the genotyping data generation and analysis pipelines. All laboratory and data analysis pipelines are modular by design, highly automated, and managed by sophisticated custom software allowing efficient handling of very large volumes of data. The DMARD Core will also release tools and pipelines under an open source plan to the community according to NIAID data sharing and release guidelines.
Open-Source Bioinformatics Tools